不知最近从哪儿刮出的一阵妖风,到处有人在鼓吹你不需要 jQuery,好像这个类库和他有什么深仇大恨似的。
为首的是这么一个项目 github…/You-Dont-Need-jQuery。项目开篇不仅说了为什么这么做,还详细列出了常用 jQuery 方法的原生实现。不愧是带头大哥,有理有据有范儿。还有一个同名的网站 youmightnotneedjquery.com,也在前端圈里流传颇广。当然还有很多跟风而起的项目站点就不一一列举了。
风起云涌之时,必然会有唱反调的。youmightnotnotneedjquery.com,看看这个 URL 是不是和上面比较像,没错只是多加了个 not 而已。
你到底站在哪一边捏?
其实两方讨论都有一个最基本的前提被我们忽视了。推荐放弃 jQuery 的一方对浏览器最低标准较为严苛,IE10+、Safari6.1+。而挺 jQuery 的一方则是从项目出发,对多浏览器的兼容以及开发效率做过对比之后得出的结论。
所以喽,我的观点是:立足现在 jQuery 仍然值得依赖,立足未来 jQuery 终归会被完善的浏览器 API 所淹没。
小剧之所以会淌这滩浑水,主要有两个原因。一是在厂内参与的桌面百度项目给前端提供了非常友好的 webkit 环境。二是个人博客的尝鲜版仅需支持 IE9+ 的浏览器,其余低版本浏览器均有另一版本作为替代。
那你提到的第一步指的是什么?
好了,若要提到 jQuery 最大的优势,那定当 dom 选择器了。今天正是拿选择器来开刀。
碰过原生 JS 的同学应该知道,原生的 dom 选择器大致有这么几个getElementById、getElementsByTagName 、getElementsByClassName,还有两个不太常用的getElementsByName、getElementsByTagNameNS。
如果是 IE8 及以上浏览器的话,还可以用querySelectorAll、querySelector这两个高级选择器。不仅支持id、class、tagname 混合查找,而且还支持属性选择器。下面是对应浏览器兼容情况,兼容情况尚且乐观,具体情况可见 caniuse.com。
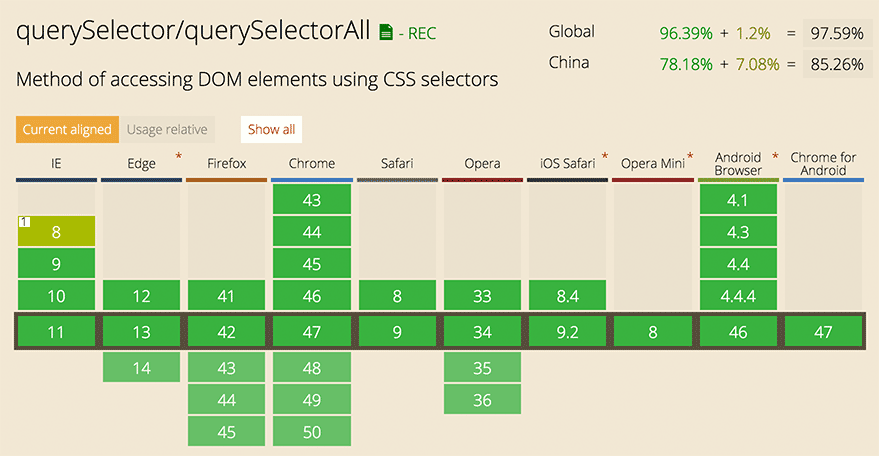
支持情况挺好,那你还要做什么?
querySelector的浏览器支持情况确实不错,看来可以直接使用而不需要任何包装。然而用惯了 element.getElementsByClassName('class') 或 $(element).find('.class')的同学会很自然的用起element.querySelector('.class')。实际用下来却会令让大伙大失所望,因为无论element是哪个元素,使用element.querySelector('.class')和document.querySelector('.class')返回的结果都是同样的。
由此可见,无法直接使用此 API 实现特定 dom 下的查找操作。即使可以通过:scope参数实现,目前也仅有 firefox 浏览器支持,确实略显鸡肋。具体实例可以查看张鑫旭前辈的一篇分析文章zhangxinxu.com。
经过上面的分析可以看出来,在 dom 获取的时候 querySelector确实可以一展神威,然而在特定元素下的检索却又束手无措。
终于到了动手干活的时候了
借鉴于 Sizzle 的经验,倒是有个取巧的方式达到 find 的效果。
如果在执行查找操作前,主动给元素添加一个 ID,再把 selector 选择器增加对应的 ID, 那么执行匹配的时候很自然地就能起到 find 查找的效果啦。若是比较幸运元素已经有了 ID 的话还可以直接使用,更为省事。
下面是完成后的代码,没有经过包装,接口只有 Query 这么一个,第一个参数是选择器字符,第二个参数为可选的 node 参数,如果有就用于实现查找范围的限定。findNode 不提供对外使用。
//ID 前缀
var private_prefix = 'Query',
//ID 加点盐
private_salt = parseInt(new Date().getTime()/1000).toString(36),
//自增索引
operate_id = 0;
//查找 DOM,仅限内部调用参数不做校验
function findNode(selector,context,queryMethod){
var id = context.getAttribute("id"),
newSelector = selector,
useID,
returns;
if(!id){
//生成临时 ID
useID = [private_prefix, private_salt, ++operate_id].join('_');
context.setAttribute('id',useID);
}else{
useID = id;
}
returns = document[queryMethod]('#' + useID + ' ' + selector);
!id && context.removeAttribute('id');
return returns;
}
/**
* 检索DOM
* selector:选择器
* context:查找对象,可选
**/
function Query(selector,context){
var returns = [],
selectorMatchs,
queryMethod = 'querySelectorAll';
//查询语句不存在或不为字符串,返回空数组
if(!selector || typeof(selector) !== 'string'){
return returns;
}
//查找对象存在,使用 find 逻辑
if(context && context.nodeType){
//匹配选择器
selectorMatchs = selector.match(/^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/);
//选择器为简单模式
if(selectorMatchs){
//ID
if(selectorMatchs[1]){
returns = [context.getElementById(selectorMatchs[1])];
}else if(selectorMatchs[2]){
//classname
returns = context.getElementsByTagName(selectorMatchs[2]);
}else{
//tagname
returns = context.getElementsByClassName(selectorMatchs[3]);
}
}else{
returns = findNode(selector,context,queryMethod)
}
}else{
//直接 query
returns = document[queryMethod](selector);
}
return returns;
}
如果你仔细看了上面的代码,会发现中间有一段正则/^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/, 用来匹配选择器是否为单纯的 ID、tagName、class。因为如果是此类选择器的话可以使用更简单更直接的方法来进行查找。
不过也挺猥琐的,这个正则匹配是我从 Sizzle 里面偷的。
这就结束了?
恩,这样就可以完成一个复杂的 DOM 选择器了,IE8+ 可以使用 CSS2 选择器,IE9+ 可以放肆地使用 CSS3选择器。当然有几个点可以视情况改进,比如增加一个接口仅匹配一个node节点;延迟 ID remove 避免不必要的反复增加删除。
终于勇敢的迈出了剿灭 jQuery 的第一步,可惜没有明哥的气场(明哥是谁?),只能止步于此。本文草草结束,over。